회사 업무 중 고객측에서 역색인만 저장 하고 원본은 저장 안했으면 한다는 이야기를 들었다.
예전에 루신 라이브러리 테스트할때 검색에는 걸리는데 원본은 없이 연관 Document만 띄우는 기능을 테스트 해본적이 있는데 그때는 그런가보다 하고 신경안썻었다 (주 사용용도가 로그 분석이다 보니 굳이 끌일이 없기에)
그러다 보니 약간 제대로 못알아들은 것도 있고 엘라스틱에서 적용 여부와 어떻게 동작이 변경 될지 몰라 다시 논의 하기로 하고 끝냈다.
루신 기반이니 어찌보면 당연한데 끄는 기능이 있다. _source 에서 지정필드만 오프 하는것(고객이 다르게 설명해서 _source off 인지 인덱싱 false인지 해깔렷다 -_-....)
루신으로 생각해보면 store 영역만 저장하는 (역색인 검색키만 저장) 기능이다.
여하간 이렇게 하면 장점은 메모리 부하나 스토리지 절감(원본을 저장 안하니 당연한) 되게 된다.
다만 그동안 굳이 끌일이 없었던 터라... 단점을 찾아보고 테스트 해본결과 무시무시한 단점이 존재 한다.
아래와 같은 단점이 있다고 한다. 번역기 돌려보면 사실상 왜 끄냐 식이다. ㅎㅎ....
사용자는 종종 결과를 생각하지 않고 _source 필드를 비활성화했다가 후회하는 경우가 많습니다. source 필드를 사용할 수 없는 경우 여러 기능이 지원되지 않습니다:
일단 심각한건 업데이트와 리인덱싱이 안된다는 것이다. 리인덱싱이야 사실 원본이 없으니 당연히 안되고 업데이트 역시 안된다고 한다.
하이라이팅의 경우도 역시 원본이 없으니 당연히 불가능 하고 버전업이나 원본 데이터 기준 집계기능(원본이 없으니뭐...) 사용 불가능 제약이 엄청 나다.
버전업 안되는건 정말 치명적인데 거대한 인덱싱을 요하는 경우 버전업시 정신이 아득해질듯 하다.
Think before disabling the_sourcefield
Users often disable the_sourcefield without thinking about the consequences, and then live to regret it. If the_sourcefield isn’t available then a number of features are not supported:
The ability to reindex from one Elasticsearch index to another, either to change mappings or analysis, or to upgrade an index to a new major version.
The ability to debug queries or aggregations by viewing the original document used at index time.
Potentially in the future, the ability to repair index corruption automatically.
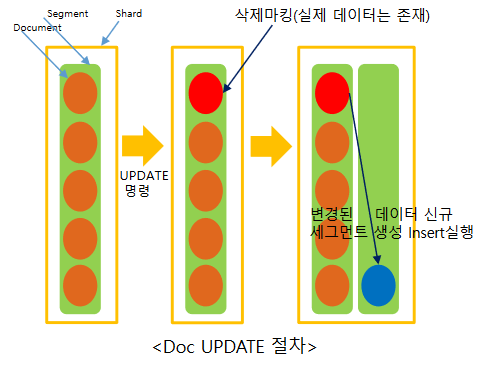
여하간 중요한건 업데이트 역시 안된다는 것이다. 엘라스틱의 기본 업데이트 구조를 생각해봤을때 당연하긴 하다.
업데이트 절차를 보면 위와 같다. 말이 업데이트지 실제는 삭제 > 인서트 이다. 이러다 보니 _id가 변경이 발생할텐데 원본색인 데이터가 없다보니 반영이 불가능 하여 검색이 되지 않는다.
다행히 최종 미팅에서 "어떻게 동작이 변경 될지 몰라 다시 논의 하기" 로 하여 대참사는 막았으나 영업이나 상위 기술쪽에서 다된다고 이미 해논거 같다. 음........
간단히 테스트 해본 자료 남겨 둔다.
(정말 간단한 테스트 이므로 복붙이 필요 없을듯 하여 스샷으로 한다.)
1. 맵핑 작업을 통해 _source에 저장 하지 않을 필드를 지정한다. (맵핑 타입은 테스트 목적상 생략했으나 text keyword등 타입은 다양하게 설정 가능 하다)
2. 가라 데이터를 넣는다.
3. 검색을 해본다. _source에서 article_content를 꺼놔서 원본은 보이지 않고 해당 document는 잘나오는걸 볼 수 있다.
역색인(Inverted Index) 에 대충 아래 표처럼 등록되어 있을 것이다.
Keyword
Document ID
sadf
SxmAhYcB1G_oFdaOqIHp, TBmBhYcB1G_oFdaO64ES
asdasd
SxmAhYcB1G_oFdaOqIHp,TBmBhYcB1G_oFdaO64ES
4. 문서하나를 업데이트 하고 검색을 해보자. test 필드 값을 변경 한뒤 검색을 진행해봤더니
"_id : TBmBhYcB1G_oFdaO64ES" 가 검색결과에서 없어졌다.
5. 물론 단순 전체 검색을 하면 동일한 아이디로 아래와 같이 보이게 된다. 하지만 역색인에서 해당 아이디는 빠지게 된다. 왜냐 위의 그림을 재탕 해보면 루씬에서 업데이트는 없다 삭제 > 생성(재생성) 이다. 삭제가 발생 했으니 역색인에서 빠지게 될 것이고 다시 재생성 할 때는 _source에 원본 텍스트가 없으니 역색인 테이블에 반영이 안되는 것이다.
역색인 테이블 활용 간단히 설명 하자면
1) 업데이트 발생시 삭제 마킹 시전 forcemerge가 발생하지 않으면 해당 상태로 둔다
Keyword
Document ID
sadf
SxmAhYcB1G_oFdaOqIHp, TBmBhYcB1G_oFdaO64ES
asdasd
SxmAhYcB1G_oFdaOqIHp,TBmBhYcB1G_oFdaO64ES
2) _source 에 없으므로 forcemerge 후 최종적으로 빠지게 될것이다.
Keyword
Document ID
sadf
SxmAhYcB1G_oFdaOqIHp
asdasd
SxmAhYcB1G_oFdaOqIHp
업데이트시에는 그냥 역색인 살려둔 상태로 하면 되지 않냐 라고 할 수 있지만... (나도 그랬음 좋겠다)
루씬의 대전제가 깨지기도 하고 해당 방법으로 하면 가득이나 느린 업데이트가 더 느릴수도 있을거같다.
비정상적(업데이트 도중 에러 등등) 상황이 나왔을때 무결성(immtable)에 문제가 발생 할수도 있어서 해당과 같은 상황이 나오는거 같다.
그동안 대에충 알고 있었는데 검증겸 테스트를 통해 명확하게 알아봤다. 언제나 그렇듯 레퍼넌스 링크는 아래에 남겨둔다.